[Active Research / Beta] Why autoregressive language models are replacing traditional neural text-to-speech pipelines, and how we are compressing models to 55M parameters.
Traditional neural text-to-speech (TTS) systems—including architectures like Tacotron, FastSpeech, and VITS—have reached their technological ceiling. These systems rely on neural regression to map input text sequences to static spectrogram coordinates, which are then passed to a neural vocoder. While computationally efficient, the resulting audio is acoustic flat: it lacks the micro-intonations, natural breathing patterns, laughter, and high-fidelity prosody that characterize human speech.
To cross the uncanny valley, speech synthesis is being reframed as a generative language modeling problem. By quantizing audio into discrete tokens (speech codes) using neural audio codecs like DAC or EnCodec, we can train a decoder-only Transformer to predict speech autoregressively. The result is a voice agent that chuckles, pauses to catch its breath, and naturally matches the cadence of conversation.
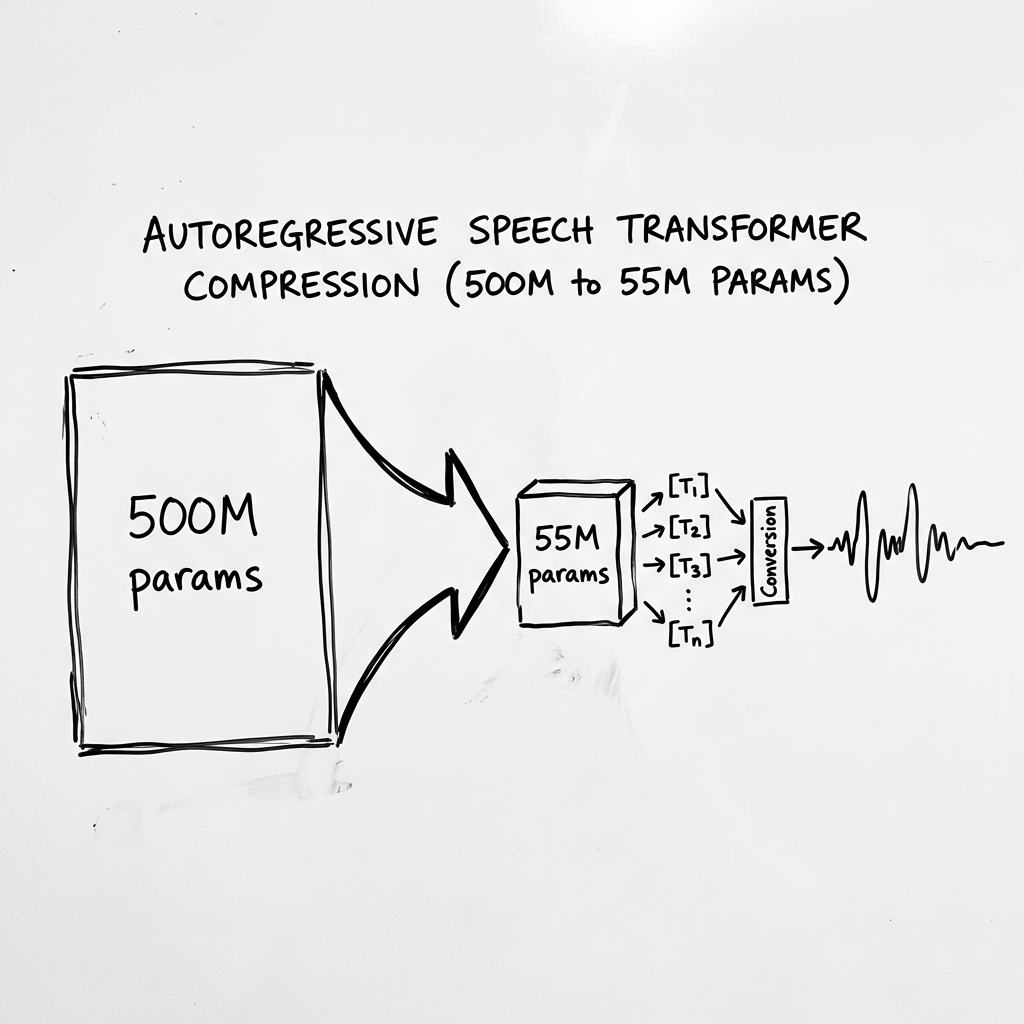
Shrinking the Transformer: 500M to 55M Parameters
Large autoregressive speech models usually range between 500M and 1B parameters, requiring significant server-side GPU resources. Running a 500M parameter model in a browser is impossible due to massive model download sizes and memory bandwidth constraints during autoregressive step generation.
We solve this constraint by compressing the model down to 55M parameters. By splitting the generation process into a small Autoregressive (AR) stage that only predicts the coarse audio token levels (the baseline acoustic features), and a non-autoregressive stage for fine-grained texture, we decrease model capacity requirements without losing voice quality.
"By focusing the autoregressive computation entirely on the primary coarse audio tokens, we achieve studio-grade speech generation within a 55M parameter budget."
Natively Compiling Speech Codecs for WebGPU
Once compressed, the model is compiled for client-side execution. Utilizing ONNX Runtime Web and WebGPU, the browser executes model inference directly on the client's hardware. Combined with INT4 quantization, the binary footprint is reduced to just 28MB, allowing it to download instantly over standard networks.
Executing the speech generation client-side eliminates server serialization overhead and network transfer times. This keeps first-byte speech latency under 90ms, delivering instant voice feedback that feels identical to human conversation. This architecture is currently in active research and developer Beta mode.
Dynamic Cache Re-use in Browser Contexts
To avoid redownloading the 28MB model binary on every page visit, we leverage browser Cache Storage API. The first time a user connects, the WebGPU shaders and model parameters are compiled and saved locally. Subsequent page loads resume instantly, enabling voice synthesis to start immediately upon connection initiation.
Technical Engineering Specs
Highly compressed speech transformer optimized for in-browser client execution.
Onset latency of speech generation via local WebGPU execution.
Compressed binary size using INT4 quantization for instant network download.
Broadcast-quality audio reconstruction using neural audio token codecs.
Experience the Intelligence
Don't just read about the engineering. Test the Vanira Core directly in your browser. Our demo agent handles multi-step tool execution with the exact protocols described above.
Start Engineering Your Voice OS
Vanira is now in open beta. Create your agents, configure your tool-calls, and integrate the SDK in minutes.