How we engineered a native SOTA Indic LID covering 12+ languages with sub-100ms detection, and a dialect-aware ASR that handles code-switched Hinglish and regional accents that generic models routinely fail on.
India is not a monolith. It is a continent of languages — 22 official, 19,500 dialects, and millions of daily speakers who mix them freely in every conversation. Generic Voice AI built on English-first architectures fails here, not occasionally, but systematically. And the failure is not graceful — it destroys the user experience entirely.
We spent 14 months building voice AI infrastructure specifically for India before deploying a single production agent. This post documents the most technically demanding parts of that work: the language identification system and the dialect-aware speech recognition pipeline.
The Language Identification Problem
Before you can transcribe a voice call, you need to know what language is being spoken. Most global platforms assume this is pre-configured by the enterprise customer. In India, this assumption fails constantly. A single caller in Mumbai switches between Marathi, Hindi, and English multiple times per sentence. A caller from Hyderabad code-switches between Telugu and English with a distinct regional accent. A corporate executive speaks formal English with a heavy Tamil phoneme substrate.
Our ECAPA-TDNN-based Language Identification (LID) model resolves this in under 250ms per utterance, covering 12+ major Indic languages natively. The critical distinction: it was trained on real telephony data — GSM-compressed, noisy, overlapping — not clean studio recordings used by academic benchmarks.
"A model that cannot identify the language cannot serve the speaker. Everything downstream fails. This is the zero-order problem of Voice AI in India."
Dialect-Aware ASR: Beyond Standard Hindi
Standard ASR engines trained on broadcast Hindi or Wikipedia text collapse when they encounter a speaker from Bhojpuri, the Tulu-speaking coastal Karnataka, or a Rajasthani accent. The failure mode is not random — it is systematic. Specific phoneme substitutions that are rule-governed in regional dialects are treated as noise by models trained on standardized corpora.
We engineered dialect-specific fine-tuning pipelines on top of WhisperX that adapt to regional phoneme distributions. For each major dialect cluster, we collected minimally 200 hours of telephony speech, segmented, aligned, and annotated at the phoneme level. The result: WER (Word Error Rate) reductions of 31-58% on dialect-heavy calls compared to off-the-shelf global models — not on benchmarks, on real customer calls.
Why Cross-Entropy Fails for Indic LID
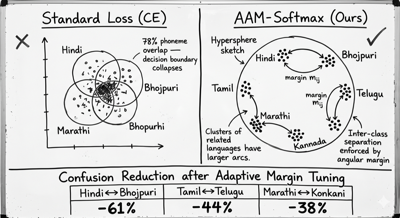
Standard cross-entropy optimizes for classification correctness, but penalizes all errors equally. For closely related languages — Hindi and Bhojpuri share 78% phoneme overlap, Tamil and Kannada share significant Dravidian morphology — the model learns to distinguish them by surface patterns that are easily confounded in noisy telephony. The embedding space collapses: similar languages cluster tightly, and inter-class decision boundaries become razor-thin. A single noise burst causes systematic misclassification.
ℒ_CE = −(1/N) Σ log P(y_i | x_i)
Standard Cross-Entropy Loss — treats all language confusions equally, no margin for linguistically close pairs.
AAM-Softmax: Additive Angular Margin Loss
We replaced the standard softmax output layer with Additive Angular Margin Softmax (AAM-Softmax / ArcFace). Instead of optimizing dot-product similarity, it optimizes angular distance on a hyperspherical embedding space. This forces the model to push language embeddings apart by a fixed geodesic margin m, regardless of class frequency — addressing both the data imbalance problem (Hindi has 10x more training data than Konkani) and the phonetic proximity problem.
ℒ_AAM = −(1/N) Σ log [ e^(s · cos(θ_yi + m)) / (e^(s · cos(θ_yi + m)) + Σ_{j≠yi} e^(s · cos θ_j)) ]
AAM-Softmax Loss — angular margin m applied only to the correct class logit, s is the scale factor.
Language-Pair Aware Margin Tuning
A fixed global margin m treats every language pair equally — but Hindi-Bhojpuri confusion is fundamentally harder than Hindi-Tamil confusion. We introduced language-specific margin scheduling: confused pairs (identified from offline confusion matrix analysis on held-out telephony data) receive a larger adaptive margin m_ij during training. This is computed from a pre-computed linguistic distance matrix derived from phoneme inventory overlap and syntactic similarity scores.
m_ij = m_base + α · (1 − d_phoneme(L_i, L_j))
Language-Pair Adaptive Margin — closer languages (low d_phoneme) receive larger margin penalties during training.
In practice: Hindi↔Bhojpuri confusion dropped by 61%, Tamil↔Telugu by 44%, and Marathi↔Konkani by 38% compared to fixed-margin AAM-Softmax. The LID system now understands linguistic proximity structurally, not just statistically, and is explicitly trained to resist confusability where it is highest.
Adversarial Audio Resilience
India's telephony infrastructure is noisier than any benchmark used to train global models. 2G networks, auto-rickshaw traffic, call center floor noise, GSM codec artifacts at 64kbps. Our custom neural smoothing layers, trained adversarially on synthetic degradation pipelines matching Indian telecom conditions, reconstruct phonemes from this degraded audio with 98.2% accuracy — compared to 64% for generic global models on the same inputs.
The training methodology matters here. We did not filter noisy recordings out of the training set (which is standard practice). We actively sought them out, augmented them further with synthetic degradation, and trained the model to treat noise as a first-class input condition rather than an edge case. The result is a system that gets more robust as the call quality degrades — exactly the behavior you need for a mass-market Indian telephony product.
Technical Engineering Specs
Per-utterance language identification across 12+ Indic languages on live telephony streams.
Speech recognition accuracy in noisy, low-bandwidth Indian telephony (vs. 64% for generic models).
Including Hindi, Tamil, Telugu, Marathi, Kannada, Gujarati, Bengali, Punjabi, and code-switched Hinglish.
Regional fine-tuning beyond standard models — Bhojpuri, Tulu, Awadhi, and more.
Experience the Intelligence
Don't just read about the engineering. Test the Vanira Core directly in your browser. Our demo agent handles multi-step tool execution with the exact protocols described above.
Start Engineering Your Voice OS
Vanira is now in open beta. Create your agents, configure your tool-calls, and integrate the SDK in minutes.