Exploring the paradigm shift of spatial intelligence, and how connecting live WebRTC video tracks to real-world objects transforms customer support and field operations.
For years, conversational AI has been confined to screen-bound interfaces: text boxes, chat bubbles, and dashboard buttons. The AI was blind to the user's physical surroundings. If a customer needed support troubleshooting a flashing red light on their home internet router, diagnosing a leaking water valve, or checking the components of a newly arrived retail package, they had to describe the physical scene in words. This visual divide makes solving real-world problems over voice calls incredibly slow and error-prone.
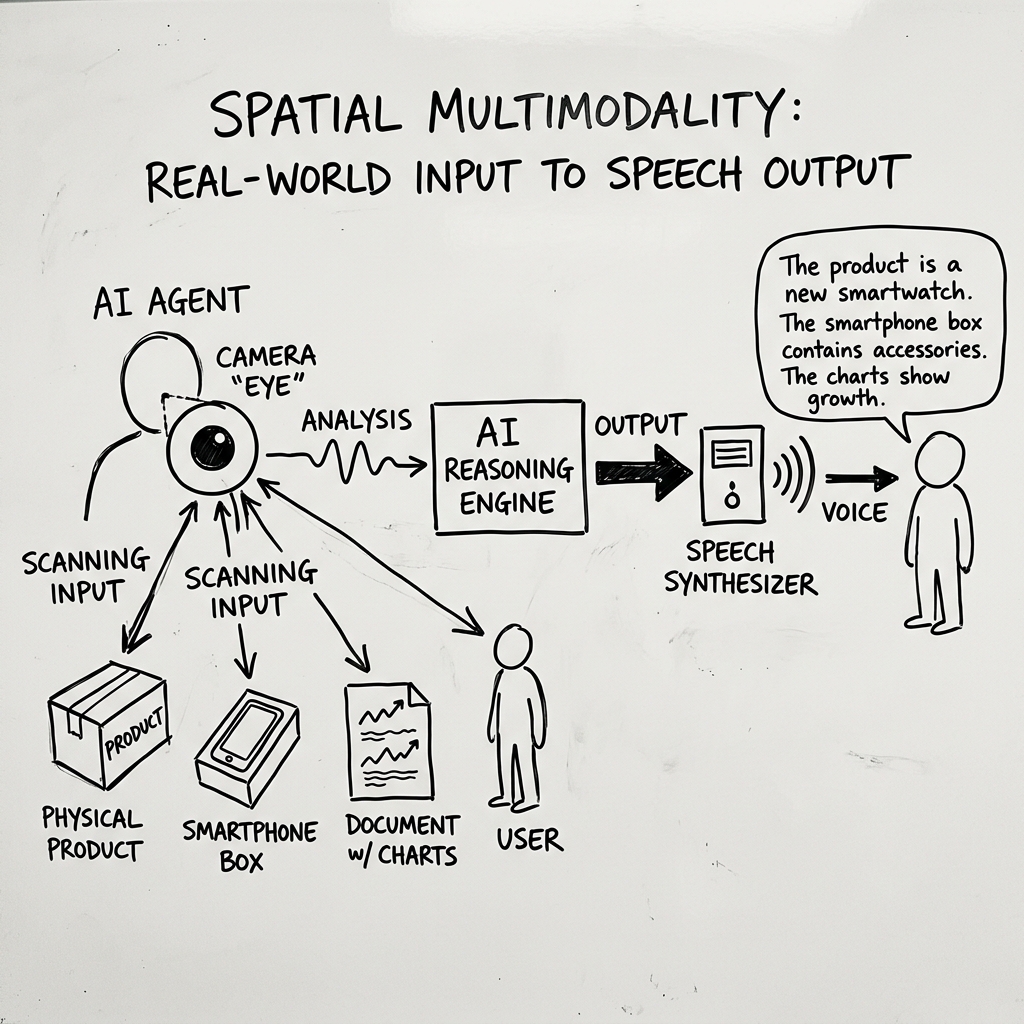
We are bridging this gap through Spatial Multimodality. By piping high-definition, low-latency video tracks from user devices directly into the active WebRTC voice session, voice agents can see, evaluate, and talk about the physical world as it changes. This shifts voice AI from a static screen companion to a physically aware assistant.
The Spatial Reasoning Pipeline
Achieving real-time spatial reasoning requires coordinating two media streams: low-latency WebRTC audio and high-resolution video frames. Standard video chat pipes visual frames to a screen, but spatial voice agents need to pipe these frames directly to visual reasoning models.
To keep latency under conversational thresholds, we avoid running full 30fps video through heavy visual transformers. Instead, the SDK uses an adaptive keyframe extraction system. The client-side stream analyzes scene changes (optical flow) and transmits high-fidelity visual frames to the multimodal reasoning engine only when there is movement, or when requested by the agent.
"Spatial intelligence isn't about processing raw video; it is about extracting key visual frames dynamically to match the conversational context."
Troubleshooting with Visual Context
Consider a home appliance troubleshooting scenario. Rather than calling a support line, the customer opens a WebRTC session and points their phone camera at the device. The voice agent instantly observes the layout and guides them: "I see your router. The power cable is plugged in, but the WAN link light is blinking orange. Let's check the blue ethernet cable connected to your wall outlet."
The agent has full awareness of spatial relations—understanding that "the blue cable" is adjacent to "the power cord". This level of guidance turns support calls into simple, interactive walkthroughs, solving issues on the spot.
Latency_total = T_frame_capture + T_spatial_inference + T_TTS_generation < 450ms
Spatial voice interaction cycle — frame extraction to verbal feedback loop time.
Transforming Field Operations and Commerce
The business applications of spatial voice agents stretch far beyond customer support. In e-commerce, customers can show a physical item to their camera and converse about it: "Do you have this smartphone model in black? How much does it cost?" In field operations, technicians can inspect industrial machinery hands-free, getting real-time verification and guides spoken to them.
As spatial reasoning architectures continue to shrink and execute closer to the edge, the boundary between digital intelligence and the physical world will disappear. Spatial multimodality represents the future of real-world interfaces.
Technical Engineering Specs
Latency from keyframe capture to conversational voice response.
Bandwidth saved by utilizing adaptive keyframe extraction over 30fps video.
Average time reduction for hardware and visual support queries.
Synchronized real-time WebRTC audio track and visual frame input streams.
Experience the Intelligence
Don't just read about the engineering. Test the Vanira Core directly in your browser. Our demo agent handles multi-step tool execution with the exact protocols described above.
Start Engineering Your Voice OS
Vanira is now in open beta. Create your agents, configure your tool-calls, and integrate the SDK in minutes.